

Las redes neuronales pueden ocultar malware y los científicos se preocupan
diciembre 15, 2021
Este artículo es parte de nuestras revisiones de artículos de investigación de IA, una serie de artículos que exploran los últimos hallazgos en inteligencia artificial.
Con sus millones y miles de millones de parámetros digitales, los modelos de aprendizaje profundo pueden hacer muchas cosas: detectar objetos en fotos, reconocer voz, generar texto y ocultar malware. Las redes neuronales pueden integrar cargas útiles maliciosas sin activar software anti-malware, según han descubierto investigadores de la Universidad de California, San Diego y la Universidad de Illinois.
Su técnica de ocultación de malware, EvilModel, arroja luz sobre las preocupaciones de seguridad del aprendizaje profundo, que se ha convertido en un tema candente de discusión en conferencias de aprendizaje automático y ciberseguridad. A medida que el aprendizaje profundo se arraiga en las aplicaciones que usamos todos los días, la comunidad de seguridad debe pensar en nuevas formas de proteger a los usuarios de las amenazas emergentes.
Ocultar malware en modelos de aprendizaje profundo
Cada modelo de aprendizaje profundo se compone de varias capas de neuronas artificiales. Dependiendo del tipo de capa, cada neurona está conectada a todas o parte de las neuronas de su capa anterior y siguiente. La fuerza de estas conexiones se define mediante parámetros digitales que están presentes durante el entrenamiento, a medida que el modelo DL aprende la tarea para la que fue diseñado. Las grandes redes neuronales pueden tener cientos de millones o incluso miles de millones de parámetros.
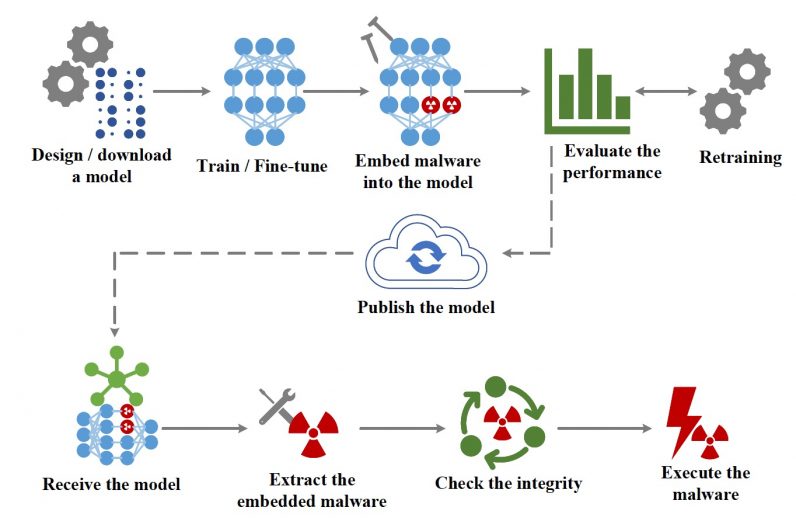
La idea principal detrás de EvilModel es incrustar malware en la configuración de una red neuronal de tal manera que sea invisible para los escáneres de malware. Es una forma de esteganografía, la práctica de ocultar un dato dentro de otro.
Al mismo tiempo, el modelo de aprendizaje profundo infectado debe realizar su tarea principal (por ejemplo, clasificar imágenes) tan bien o casi como un modelo limpio para evitar levantar sospechas o inutilizarlo para sus víctimas.
Finalmente, el atacante debe tener un mecanismo para entregar el modelo infectado a los dispositivos de destino y extraer el malware de los parámetros de la red neuronal.
Modificación de valores de parámetros
La mayoría de los modelos de aprendizaje profundo utilizan números de punto flotante de 32 bits (4 bytes) para almacenar valores de parámetros. Según las experiencias de los investigadores, un atacante puede almacenar hasta 3 bytes de malware en cada parámetro sin afectar significativamente su valor.

Cuando infecta el modelo de aprendizaje profundo, el atacante divide el malware en fragmentos de 3 bytes e incrusta los datos en su configuración. Para enviar el malware al objetivo, el atacante puede publicar la red neuronal infectada en una de las muchas ubicaciones en línea que albergan modelos de aprendizaje profundo como GitHub o TorchHub. Alternativamente, el atacante puede organizar una forma más complicada de ataque a la cadena de suministro, donde el modelo infectado se entrega a través de actualizaciones automáticas del software instalado en el dispositivo de destino.
Una vez que el modelo infectado se entrega a la víctima, el software extrae la carga útil y la ejecuta.
Ocultar malware en redes neuronales convolucionales
Para verificar la viabilidad de EvilModel, los investigadores lo probaron en varias redes neuronales convolucionales (CNN). Hay varias razones que hacen de las CNN un estudio interesante. Primero, son bastante grandes, por lo general contienen decenas de capas y millones de parámetros. En segundo lugar, contienen una arquitectura diversa y engloban diferentes tipos de capas (totalmente conectadas, convolucionales) y diferentes técnicas de generalización (normalización por lotes, capas de aborto, capas de agrupación, etc.), lo que permite evaluar los efectos de la integración de malware en varios escenarios. En tercer lugar, las CNN se utilizan ampliamente en aplicaciones de visión por computadora, lo que podría convertirlas en un objetivo principal para los actores malintencionados. Y finalmente, hay muchas CNN previamente capacitadas que están listas para ingresar a las aplicaciones sin ningún cambio, y muchos desarrolladores están utilizando CNN previamente capacitadas en sus aplicaciones sin necesariamente saber cómo funciona el aprendizaje profundo bajo el capó.
Los investigadores primero intentaron integrar malware en AlexNet, una CNN popular que ayudó a revivir el interés en el aprendizaje profundo en 2012. AlexNet tiene un tamaño de 178 megabytes y tiene cinco capas convolucionales y tres capas densas (o completamente conectadas).
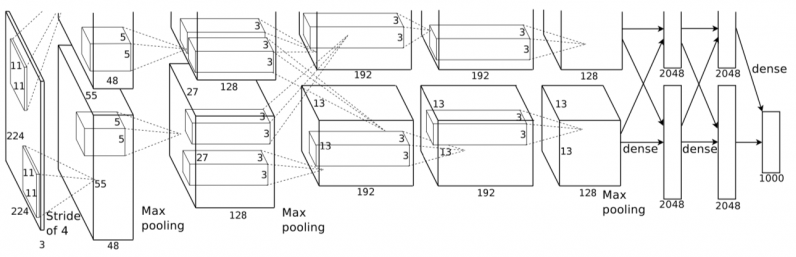
Cuando AlexNet se entrenó con la normalización por lotes, una técnica que estandariza los ejemplos de entrenamiento en grupos antes de ejecutarlos a través del modelo de aprendizaje profundo, los investigadores pudieron colocar 26,8 megabytes de malware en el modelo, manteniendo su precisión al 1% de la versión limpia. . Si aumentaran el volumen de datos de malware, la precisión comenzaría a disminuir drásticamente.
Luego intentaron reciclar el modelo después de infectarlo. Al congelar las neuronas infectadas, evitaron que se alteraran durante los ciclos de entrenamiento adicionales. Con la normalización y el reciclaje de lotes, los investigadores podrían aumentar el volumen de datos de malware a 36,9 megabytes mientras se mantiene la precisión del modelo por encima del 90%.
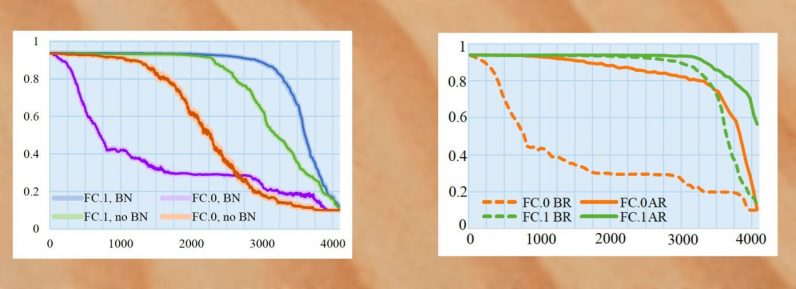
Los modelos se infectaron con ocho muestras de la base de datos de InQuest, todas las cuales fueron reconocidas como malware por el escáner en línea VirusTotal. Una vez que las muestras se integraron en las redes neuronales, el modelo completo se cargó en VirusTotal, pero se marcó como seguro, lo que demuestra que el malware estaba bien oculto.
Los investigadores probaron la técnica en varias otras arquitecturas de CNN, incluidas VGG, Resnet, Inception y Mobilenet. Obtuvieron resultados similares, que muestran que la integración de malware es una amenaza universal para las grandes redes neuronales.
Canalizaciones seguras de aprendizaje automático
Dado que los escáneres de malware no pueden detectar cargas útiles maliciosas integradas en modelos de aprendizaje profundo, la única contramedida contra EvilModel es destruir el malware.
La carga útil conserva su integridad solo si sus bytes permanecen intactos. Por tanto, si el destinatario de un EvilModel recicla la red neuronal sin congelar la capa infectada, los valores de sus parámetros cambiarán y los datos del malware serán destruidos. Incluso un solo período de entrenamiento es probablemente suficiente para destruir cualquier malware integrado en el modelo DL.
Sin embargo, la mayoría de los desarrolladores usan modelos previamente entrenados tal cual, a menos que quieran refinarlos para otra aplicación. Y algunas formas de ajuste congelan la mayoría de las capas existentes en la red, que pueden incluir capas infectadas.
Esto significa que, junto con los ataques adversos, el envenenamiento de datos, la inferencia de extremidades y otros problemas de seguridad conocidos, las redes neuronales infectadas con malware representan una amenaza real para el futuro del aprendizaje profundo.
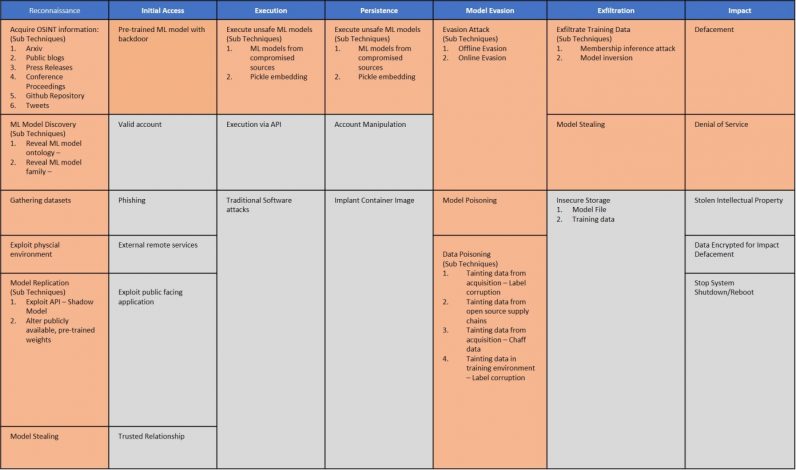
Las diferencias entre los modelos de aprendizaje automático y el software tradicional basado en reglas requieren nuevas formas de pensar sobre las amenazas a la seguridad. A principios de este año, varias organizaciones introdujeron Adversarial ML Threat Matrix, un marco que ayuda a encontrar debilidades en las canalizaciones de aprendizaje automático y corregir los agujeros de seguridad.
Si bien Threat Matrix se centra en los ataques adversarios, sus métodos también son aplicables a amenazas como EvilModels. Hasta que los investigadores encuentren métodos más robustos para detectar y bloquear malware en redes neuronales profundas, debemos establecer una cadena de confianza en las canalizaciones de aprendizaje automático. Sabiendo que los escáneres de malware y las herramientas de análisis estático no pueden detectar modelos infectados, los desarrolladores deben asegurarse de que sus modelos provengan de fuentes confiables y que la procedencia de los datos de entrenamiento y los parámetros aprendidos no se vea comprometida. A medida que continuamos aprendiendo más sobre la seguridad del aprendizaje profundo, debemos tener cuidado con lo que se esconde detrás de los millones de dígitos que se calculan para analizar nuestras fotos y reconocer nuestras voces.
Este artículo fue publicado originalmente por Ben Dickson en TechTalks, una publicación que examina las tendencias tecnológicas, cómo afectan la forma en que vivimos y hacemos negocios, y los problemas que resuelven. Pero también discutimos el lado malo de la tecnología, las implicaciones más oscuras de la nueva tecnología y qué buscar. Puedes leer el artículo original aquí.

